今回は、Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks (Xu, Weilin, David Evans, and Yanjun Qi., 2017)の論文に目を通したので、論文メモとしてBlogに残しておきます。
Fig. 1: Feature-squeezing framework for detecting adversarial examples.
Abstract
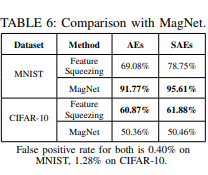
Although deep neural networks (DNNs) have achieved great success in many tasks, they can often be fooled by adversarial examples that are generated by adding small but purposeful distortions to natural examples. Previous studies to defend against adversarial examples mostly focused on refining the DNN models, but have either shown limited success or required expensive computation. We propose a new strategy, feature squeezing, that can be used to harden DNN models by detecting adversarial examples. Feature squeezing reduces the search space available to an adversary by coalescing samples that correspond to many different feature vectors in the original space into a single sample. By comparing a DNN model’s prediction on the original input with that on squeezed inputs, feature squeezing detects adversarial examples with high accuracy and few false positives. This paper explores two feature squeezing methods: reducing the color bit depth of each pixel and spatial smoothing. These simple strategies are inexpensive and complementary to other defenses, and can be combined in a joint detection framework to achieve high detection rates against state-of-the-art attacks.
It is known that deep neural networks (DNNs) are vulnerable to adversarial attacks. The so-called physical adversarial examples deceive DNN-based decisionmakers by attaching adversarial patches to real objects. However, most of the existing works on physical adversarial attacks focus on static objects such as glass frames, stop signs and images attached to cardboard. In this work, we proposed adversarial T-shirts, a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person's pose changes. To the best of our knowledge, this is the first work that models the effect of deformation for designing physical adversarial examples with respect to-rigid objects such as T-shirts. We show that the proposed method achieves74% and 57% attack success rates in the digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate. Furthermore, by leveraging min-max optimization, we extend our method to the ensemble attack setting against two object detectors YOLO-v2 and Faster R-CNN simultaneously.
Figure 7: Sample frames from our attack videos after being processed by YOLO v2. In the majority of frames, the detector fails to recognize the Stop sign.
Abstract
Deep neural networks (DNNs) are vulnerable to adversarial examples-maliciously crafted inputs that cause DNNs to make incorrect predictions. Recent work has shown that these attacks generalize to the physical domain, to create perturbations on physical objects that fool image classifiers under a variety of real-world conditions. Such attacks pose a risk to deep learning models used in safety-critical cyber-physical systems. In this work, we extend physical attacks to more challenging object detection models, a broader class of deep learning algorithms widely used to detect and label multiple objects within a scene. Improving upon a previous physical attack on image classifiers, we create perturbed physical objects that are either ignored or mislabeled by object detection models. We implement a Disappearance Attack, in which we cause a Stop sign to "disappear" according to the detector-either by covering thesign with an adversarial Stop sign poster, or by adding adversarial stickers onto the sign. In a video recorded in a controlled lab environment, the state-of-the-art YOLOv2 detector failed to recognize these adversarial Stop signs in over 85% of the video frames. In an outdoor experiment, YOLO was fooled by the poster and sticker attacks in 72.5% and 63.5% of the video frames respectively. We also use Faster R-CNN, a different object detection model, to demonstrate the transferability of our adversarial perturbations. The created poster perturbation is able to fool Faster R-CNN in 85.9% of the video frames in a controlled lab environment, and 40.2% of the video frames in an outdoor environment. Finally, we present preliminary results with a new Creation Attack, where in innocuous physical stickers fool a model into detecting nonexistent objects.
Figure 5: Patch created by the Creation Attack, aimed at fooling YOLO v2 into detecting nonexistent Stop signs.
Figure 6: Sample frame from our creation attack video after being processed by YOLO v2. The scene includes 4 adversarial stickers reliably recognized as Stop signs.
Fig. 1: Adversarial sample generation - Distortion is added to input samples to force the DNN to output adversary selected classification
Abstract
Deep learning takes advantage of large datasets and computationally efficient training algorithms to outperform other approaches at various machine learning tasks. However, imperfections in the training phase of deep neural networks make them vulnerable to adversarial samples: inputs crafted by adversaries with the intent of causing deep neural networks to misclassify. In this work, we formalize the space of adversaries against deep neural networks (DNNs) and introduce a novel class of algorithms to craft adversarial samples based on a precise understanding of the mapping between inputs and outputs of DNNs. In an application to computer vision, we show that our algorithms can reliably produce samples correctly classified by human subjects but misclassified in specific targets by a DNN with a 97% adversarial success rate while only modifying on average 4.02% of the input features per sample. We then evaluate the vulnerability of different sample classes to adversarial perturbations by defining a hardness measure. Finally, we describe preliminary work outlining defenses against adversarial samples by defining a predictive measure of distance between a benign input and a target classification.
Figure 1: A demonstration of fast adversarial example generation applied to GoogLeNet (Szegedy et al., 2014a) on ImageNet.
Abstract
Several machine learning models, including neural networks, consistently misclassify adversarial examples---inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks' vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset.
Open Redirectは、攻撃者が任意の外部ドメインにリダイレクトさせるURLを作成できる脆弱性です。
Open Redirect脆弱性の検出アルゴリズムはPayloadを載せたリクエストを送り、返ってきたレスポンスのLocationヘッダがhttp://example.comを指していればとOpen Redirectの脆弱性が存在すると判断するアルゴリズムです。文字列の部分一致を用いてLocationヘッダの判断をしています。
HimawariはBlack Box型の診断ツールです。BlackBox型とは、リクエストとレスポンスから脆弱性が存在するかどうかを判断する方法です。
White Box型の診断ツールと違い、実際のソースコードから全体の構造やロジックを確認することはできないため、診断対象の明確な仕様書がなければ隅々までテストを行うことは難しい場合が存在します。
Black Box型の診断ツールはWebアプリケーションに関わっていない第三者でも、情報セキュリティに詳しくない人にでも非常に簡単に診断を行うことができますが、全ての脆弱性を検出することはとても難しいということをユーザは頭に入れて診断ツールを利用すべきです。
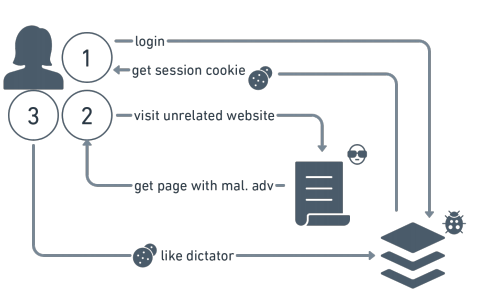
Calzavara, Stefano, et al. "Machine learning for web vulnerability detection: the case of cross-site request forgery." IEEE Security & Privacy 18.3 (2020): 8-16.
In this article, we propose a methodology to leverage Machine Learning (ML) for the detection of web application vulnerabilities. Web applications are particularly challenging to analyse, due to their diversity and the widespread adoption of custom programming practices. ML is thus very helpful for web application security: it can take advantage of manually labeled data to bring the human understanding of the web application semantics into automated analysis tools. We use our methodology in the design of Mitch, the first ML solution for the black-box detection of Cross-Site Request Forgery (CSRF) vulnerabilities. Mitch allowed us to identify 35 new CSRFs on 20 major websites and 3 new CSRFs on production software.