こんにちは,ふたばとです.
今回は最近開発している自作の連合学習フレームワーク『FutabatedLearning』を紹介をしてみようと思います.
最低限人に見せられるよう整えたので LICENSE を MIT にしてリポジトリを公開しました.
連合学習とは,機械学習におけるプライバシーの保護に重点を置いた学習手法です.
一般的な機械学習を1つの中央のサーバにデータを集約してそのサーバ上でモデルを作成することとすれば,連合学習は中央のサーバと複数のクライアントとで構成されており,クライアントは分散しています.各クライアントは自身が所持するデータセットを用いてローカルで学習した結果を中央サーバに送信します.中央のサーバは各クライアントから送られてきた学習結果を適切に集約することで,1つのグローバルモデルを作成します.
学習に用いるデータはクライアント上にあるため,連合学習は規制の問題を回避したり,インフラにかかるコストを抑えられたりするメリットがあります.
自作している連合学習フレームワーク『FutabatedLearning』は Researcher Experience の高いシステムを目指して開発している,連合学習のフレームワークです.
あくまで研究用に小回りが利くことを意識しているため,実用的な連合学習はあまり想定できていません.
コードの再利用性のために Hydra で YAML を設定して実験の設定ができるようにしていて,実験は MLflow でロギングしているため実験同士の比較を WebUI で簡単に行うことができます.
また,Docker, Poetry, DevContainer で環境を構築しているため,コードを動かすためのツラミを最小限にしようとしています.
本稿では FutabatedLearning の簡単な紹介を行いますが,その前に連合学習の基本的な説明をしておこうと思います.
連合学習の概要
連合学習(Federated Learning) は 2016 年に Google より提唱されました.*1
連合学習のコンセプトは,データ漏洩を防ぎながら,複数のデバイスに分散されたデータセットに基づいて機械学習モデルを構築することにあります.*2
一般的な機械学習を1つの中央のサーバにデータを集約してそのサーバ上でモデルを作成することとすれば,連合学習は中央のサーバと複数のクライアントとで構成されており,クライアントは分散しています. ここでいうクライアントは,組織や各個人が所有するデバイスが当てはまります.
連合学習は通信コストを制約として,学習データをクライアントが保持することでサーバがデータを保持する必要性を解消します.
サーバはまずグローバルモデルを各クライアントに配信します.グローバルモデルを受け取った各クライアントは自身が持つデータセットを用いてグローバルモデルをローカルで学習させ,学習の結果得られるクライアント固有のモデルの更新情報をサーバに送信します.
サーバはクライアントから送信されたモデルの更新情報を集約して1つにまとめ,グローバルモデルを更新します.
この過程を1ラウンドとして,このラウンドを繰り返すことで連合学習は学習が進んでいきます.

もう少し具体的なアルゴリズムは後ほど見ていきますが,
このような学習プロセスを歩むことで,学習データは各クライアント上に保持したまま1つのモデルを作成する共同学習を実現できます.
モチベーション
では,どうしてデータセットを中央のサーバに集約するのではなく,クライアント上で保持すると嬉しいのでしょうか.
連合学習が台頭する背景には,機械学習が抱えるデータに関する規制の問題やユーザの好みの問題,インフラにかかるコストの問題が存在していました.
規制の問題
2018 年に EU で施行された GDPR*3 では,個人情報は基本的人権として見做されています. これは 1983 年にドイツ連邦憲法裁判所で情報自己決定権という概念が定式化され,今日の GDPR へ継承されています.
日本の法律でいうと,2022年4月1日に改正個人情報保護法が施行されました.*4
改正個人情報保護法には、日本国内のユーザーの、個人に帰属する情報(PRI)の処理に関する規則が含まれます。改正個人情報保護法では、企業が日本国内のユーザーの PRI を「個人情報」に関連付ける可能性が高い第三者に提供する際、企業は、データの受領者がデータを処理することについてユーザーから同意を得て記録していることを、データの受領者に確認することが義務付けられています。PRI は通常、それ自体は特定の個人を識別しない識別子(Cookie ID など)によって収集され、(個人情報保護法で定義される)個人データと関連付けられる形で保存されることはありません。
世界の異なる地域のデータは,その地域のデータの保護規則によって管理されるため,単一の組織が持つ自分たちデータさえも学習に利用できないことさえあります.
ユーザの好みの問題
規制の問題とは別に,ユーザの好みの問題も存在します.
後ほどユースケースで紹介する事例とともに説明すると,個人が持つデバイスに在る機微なデータ(例えば,キーワードで入力された文字列)を利用したい場合,規制の問題を回避できていたとしても入力情報が外部のサーバに送信されることは,ユーザは好ましく思わないでしょう.
実際にこのようなユースケースに存在する問題を解決するために生まれたのが,連合学習になります.
インフラにかかるコストの問題
データを1つのサーバに一元的に集約することは,インフラにかかるコストが大きくなります.
データを集約せずにクライアントが保持したまま学習することができれば,データを保持するための中央集権的なインフラが不要になるメリットがあります.
事例とユースケース
先述したデータの扱いに関する多面的な問題を機械学習は抱えていたために,昨今の盛り上がりを見せる機械学習技術の恩恵を受けられないユースケースが存在していました.
連合学習の台頭によって,中央サーバにデータを集約することが難しいユースケースにおいても機械学習の恩恵を受けられる連合学習が注目されているということがわかります.
連合学習は研究だけに留まらずに実用化もされているので,ここでは事例とともにユースケースを紹介します.
連合学習は学習に参加するクライアントと作成するモデルの規模に基づいて,クロスデバイス学習とクロスサイロ学習の2つのタイプに分類することができます.
クロスデバイス学習
クロスデバイス学習におけるクライアントは,IoT デバイスやスマートフォンが当てはまります.
学習に参加するクライアントの数は数千のオーダになる場合もあります.
連合学習の収束を早めるためのアルゴリズムの研究がありますが,それらの研究はこのクロスデバイス学習の問題設定を利用していることが多いです.
クロスデバイス学習の事例として,ユーザが所持するスマートフォンの予測変換データを用いた連合学習の事例があります.
クロスサイロ学習
クロスサイロ学習におけるクライアントは,病院のような組織などエンティティが当てはまります.
ここでいうサイロとは,各エンティティが保持する,分離・独立したリポジトリであることを指しています.
クロスデバイス学習は単一組織内の分散化されたデバイス間でモデルを学習することに重点が置かれていることが多い一方で,クロスサイロ学習は単一組織の境界を越えます.
クロスサイロ学習の事例として,『Federated learning for predicting clinical outcomes in patients with COVID-19』が有名です.
医療情報を扱うデータで連合学習をやるには,クロスサイロ学習のアプローチを利用することになると考えられます.
連合学習の種別
連合学習は水平連合学習と垂直連合学習に分けることができ,各クライアントが所持するデータの構造や連合学習のタスクに応じて適用手法が異なります.
本稿で取り上げるものを含め,連合学習の多くは水平連合学習と呼ばれるものになります.
水平連合学習はテーブルデータを思い浮かべるとイメージしやすいかと思います.
水平連合学習
水平連合学習(Horizontal Federated Learning)は,各クライアントが同じ特徴量を持つが,サンプル(言うなれば ID)が異なるデータ構造の場合に適用できます.
単純に学習に使えるデータがクライアントの分だけ増えると捉えて問題ないでしょう.
水平連合学習の目標は,すべてのクライアントのデータセットに渡ってうまく汎化できるグローバルモデルを学習することになります.
垂直連合学習
垂直連合学習(Vertical Federated Learning)は,各クライアントで同じサンプルであるが,異なる特徴量を持つデータ構造の場合に適用可能です.
これは組織間で収集しているデータは異なるものの,法的な観点で共有することができないケースに有効な学習手法であると言えるでしょう.
垂直連合学習で学習するには,ID の整合性を取る必要があります.
ID を突合して,全クライアントとサーバみんなで協力してグローバルモデルを作成していきます.
基本的なアルゴリズム
どのように集約をするのかでもさまざまな研究が行われていますが,
今回は,FedAVG*5 という代表的な集約アルゴリズムを例に,連合学習の基本的なアルゴリズムを確認していきます.
B: ローカルミニバッチサイズE: ローカルエポック数η: 学習率K: クライアントの数k: クライアントの IndexC: 各ラウンドにおける学習に参加するクライアントの割合Pk: クライアントk上のデータポイントの Index の集合w: モデルのパラメータ∇l(w; b): 損失関数l(w; b)の勾配

Server executes
- ラウンド 0 としてグローバルモデル
wを初期化する - ラウンド
t = 1, 2, ...の間以下の処理を行う- 学習に参加するクライアントをランダムに
m個選択する - 各クライアントについて,以下の処理を並列に行う
- クライアントの Index
k, とラウンドtにおけるグローバルモデルw_tを引数にClientUpdateを呼び出し,返り値を クライアントkにおけるラウンドt+1のモデルとする
- クライアントの Index
- 学習に参加しているクライアントから送られてきたモデルの更新情報の加重平均を取り,ラウンド
t+1におけるグローバルモデルとする
- 学習に参加するクライアントをランダムに
FutabatedLearning での実装は以下のとおりです.
def average_weights( local_weights: list[dict[str, torch.Tensor]], ) -> dict[str, torch.Tensor]: """ Averages the weights from multiple state dictionaries (each representing model parameters). Args: local_weights (list of dict): A list where each element is a state dictionary of model weights. Returns: A dict of the same structure as the input but with averaged weights. """ # Initialize the averaged weights with deep copied weights from the first model weight_avg: dict[str, torch.Tensor] = copy.deepcopy(local_weights[0]) # Iterate over each key in the weight dictionary for weight_key in weight_avg.keys(): # Sum the corresponding weights from all models starting from the second one for weight_i in range(1, len(local_weights)): weight_avg[weight_key] += local_weights[weight_i][weight_key] # Divide the summed weights by the number of models to get the average weight_avg[weight_key] = torch.div( weight_avg[weight_key], len(local_weights) ) # Return the averaged weights return weight_avg
ClientUpdate(k, w)
- クライアントの持つデータ
PkをサイズBで分割する E回以下の処理を行う- ミニバッチ
bを用いて以下の処理を行う- ミニバッチ勾配降下法
w := w - η∇l(w; b)でモデルを更新する
- ミニバッチ勾配降下法
- ミニバッチ
wを Server に送信する
FutabatedLearning での実装は以下のとおりです.
class LocalUpdate(object): (snip) # Perform local training and update weights def update_weights( self, model: nn.Module, global_round: int ) -> tuple[dict[str, torch.Tensor], float]: # Set the model to training mode model.train() epoch_loss: list[float] = [] # Initialize an optimizer based on the selected configuration optimizer: torch.optim.Optimizer if self.cfg.train.optimizer == "sgd": optimizer = torch.optim.SGD( model.parameters(), lr=self.cfg.train.lr, momentum=0.5 ) elif self.cfg.train.optimizer == "adam": optimizer = torch.optim.Adam( model.parameters(), lr=self.cfg.train.lr, weight_decay=1e-4 ) # Iterate over the local epochs for iter in range(self.cfg.train.local_epochs): batch_loss: list[float] = [] # Loop over the training data batches for batch_idx, (images, labels) in enumerate(self.trainloader): # Move batch data to the computing device images, labels = images.to(self.device), labels.to(self.device) # Reset gradients to zero model.zero_grad() # Forward pass log_probs = model(images) # Calculate loss loss = self.criterion(log_probs, labels) # Backward pass loss.backward() # Update weights optimizer.step() # Add loss to the logger mlflow.log_metric( f"loss-client{self.client_id}", loss.item(), step=global_round, ) # Add the current loss to the batch losses list batch_loss.append(loss.item()) # Compute average loss for the epoch epoch_loss.append(sum(batch_loss) / len(batch_loss)) # Return the updated state dictionary of the model and the average loss for this round weight: dict[str, torch.Tensor] = model.state_dict() # Calculate the average loss from the collected epoch losses. average_loss: float = sum(epoch_loss) / len(epoch_loss) return weight, average_loss
データセット
筆者は自然言語処理分野やテーブルデータには疎いので,主に画像認識分野で使われるデータセットの紹介になります.
有名どころでは,CIFAR-10 / CIAFR-100 *6,MNIST*7,EMNIST*8 が非常によく使われています.ImageNet*9,COCO*10 などの画像認識分野で著名な大規模データセットはほとんど見かけない印象です.
上記のデータセットは一般的な画像認識で利用可能なデータセットになりますが,連合学習用のデータセットとして,FEMNIST や CelebA*11 が存在しており,これらもよく使われています.
FEMNIST や CelebA は CMU から出されている LEAF*12 という連合学習用のベンチマーキングフレームワークにまとまっています.
LEAF が提供するデータセット名とそのタスクは以下のとおりです.
- FEMNIST: Image Classification
- Sentiment140: Sentiment Analysis
- Shakespeare: Next-Character Prediction
- CelebA: Image Classification (Smiling vs. Not smiling)
- Synthetic Dataset: Classification
- Reddit: Next-word Prediction
昨年 LEAF の導入記事を公開したので,併せてご覧ください.
IID vs Non-IID
今紹介した FEMINST を略さずに表現すると,Federated Extended MNIST になります. Federated Learning 用のデータセットとは,どのような意味合いになるのでしょうか.
連合学習の文脈では,扱うデータセットは IID と Non-IID の2つに分類されます. IID とは,Independently and Identically Distributed data の略で,統計学や確率論におけるデータの性質を表すのに使われる用語です.
理想的なデータの分布から考えてみましょう.
理想的なデータの分布は「連合学習に参加する全クライアントのラベルの分布が一致していること」になります.
このようなデータの環境は IID に従うデータセットと表現されます.
IID に従うデータセットを作成するには,単に MNIST のような既存のデータセットをクライアントの数で割り,ラベルの分布も一様に分散させてやればよいので,実験環境としては比較的容易に準備することができると考えられます.
しかし現実的なデータセットを考えると,IID のような理想的なケースにはならないことがほとんどであると考えられます.
クライアント毎に所持するデータの量やラベルの分布が異なるだけでなく,データの品質も異なるでしょう.実行時の特性も異なるかもしれません.
このようなデータの環境は Non-IID に従うデータセットと表現されます.
Non-IID に従うデータセットを扱うということは,各クライアント上で学習される個々のモデルの重みには大きな違いが発生するため,FedAVG のような単純な集約手法では良いグローバルモデルを得ることが難しくなることが考えられます.
このため,連合学習では Non-IID の訓練データを持つクライアントの多様性を考慮しながら学習を進めていく必要があります.
実運用の連合学習では基本的に Non-IID に従うデータを扱うことになるため,ファーストステップとして IID に従うデータでうまくいく研究をすることがまず重要ですが,実社会への適用を目指すには Non-IID に従うデータセットにも対応していく必要があります.
評価
もちろん連合学習が解くタスクによって評価指標は変わりますが,論文を見ている限り多いのはまず Accuracy です.
タスクによっては,F1-Score や Precision, Recall を利用しているものもありますが,CIFAR-10 などの一般的なデータの場合には Accuracy が使われます.
さらに連合学習で性能を測る場合,精度さえ算出できればよいというわけでもなく,計算効率・通信効率・安全性を評価していく必要があります.
計算効率や通信効率は,1ラウンドあたりにかかる時間や,ある地点における時間やラウンド数で評価します.
安全性は,のちに紹介する攻撃手法の攻撃の成功率で評価します.
さまざまな角度で議論する必要があるため,網羅的に評価できる指標を作るのはとても難しい印象があります.
セキュリティの問題
連合学習のプロトコルはまだまだ発展途上です.
プライバシーに配慮した学習手法であるために学習にかかる時間は一般的な学習手法に比べると長くなってしまいます.
コミュニケーションコストを抑えつつも効率的にグローバルモデルを収束させる研究が盛り上がっている一方で、連合学習におけるセキュリティの問題も多く研究されています.
連合学習の抱えるセキュリティの問題は大きく2つ,プライバシー保証の問題とロバスト性保証の問題があります.
プライバシー保証の問題
プライバシー保証の問題とは,「クライアントが送信した情報から学習データは漏洩しないのか?」という問題です.
学習に利用するデータセットは各クライアントが所持し,学習した結果のみをサーバへ送るため,連合学習はプライバシーに配慮した学習手法であるとされていますが,クライアントが送信した情報から学習データを復元・盗取する Model Inversion Attack*13 と呼ばれる攻撃手法が存在します.その他の攻撃手法として,あるデータがデータセットに含まれているかを特定するメンバーシップ推論 (Membership Inference)*14 も有名です.
現状ではデータが漏洩しないことを理論的に保証する差分プライバシー (Differental Privacy) 技術や,準同型暗号 (Homomorphic Encryption) や MPC(Multi-Party Computation),TEE を利用して暗号化によって盗聴されても情報が漏洩されない仕組みを用いることが代表的な防御手法として挙げられます.
また,クライアントからの個別の情報を漏洩させずに集約する手法は,Secure Aggregation と呼ばれます.
ロバスト性保証の問題
ロバスト性保証の問題とは,「学習の収束が妨害されてもうまく学習が回るのか?」という問題です.
連合学習はプライバシーに配慮した学習手法であるため,サーバはクライアントが提示する情報が本物であるかを確認する術はありません.
学習に参加している一部のクライアントが悪意を持って実際の学習結果と異なる情報をサーバへ送信した場合,グローバルモデルの収束が妨害され,連合学習全体が崩壊してしまいます.
このような攻撃手法はビザンチン攻撃 (Byzantine Attack) と呼ばれ,実際に FedAVG のような線形結合で集約する手法は,攻撃者に集約された勾配の完全な制御を与えるということが指摘されています.*15
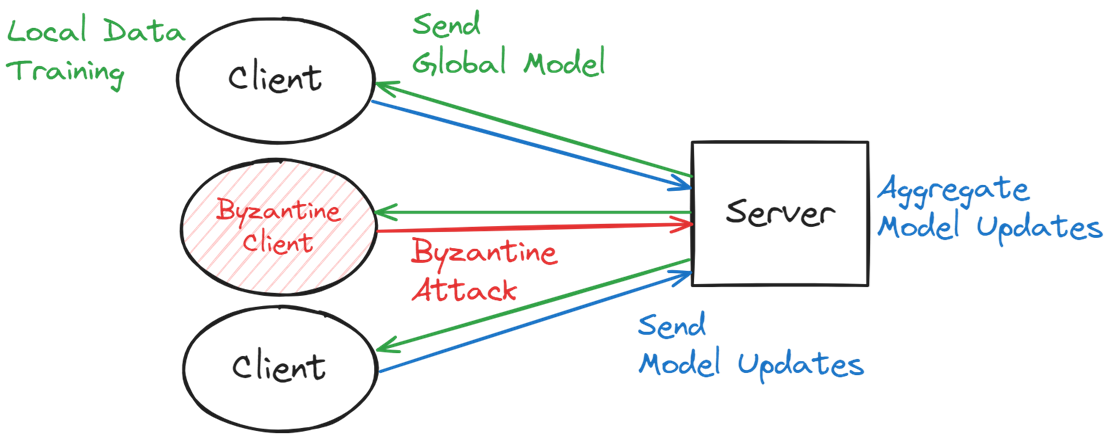
基本的な防御手法は異常値除去処理です.
一部のクライアントが異常な行動をしても全体としてうまく処理が続けられる頑健性のことをビザンチン耐障害性 (Byzantine Fault Tolerance)*16 と呼ばれ,連合学習にビザンチン耐障害性をどのように組み込むかという研究がされています.
オープンソースプロジェクト
最後に,連合学習のオープンソースプロジェクトをいくつか紹介します.
TFF
Flower
IBM Federated Learning
PySyft
Fate
FedML
FedLab
FutabatedLearning の紹介
さて,自作の連合学習フレームワーク『FutabatedLearning』の話に移ります.
FutabatedLearning は,Researcher Experience の高いシステムを目指して開発している連合学習のフレームワークです.
名前は完全に見た目が FederatedLearning っぽいという理由でつけました.口に出したときの語感も好きです.
Flower をはじめとする連合学習フレームワークは非常によくできていて,すぐにでも実用に向けた実験ができるかもしれません.しかしセキュリティの実験を行うにはやや壮大で,私は追いきれませんでした.
実験者はどこでどんな処理が行われているのかを把握できている必要があると考えており,全体像を把握しきれる程度の規模であることが重要だと考えました.
また,実験管理ツールを導入することでコードの再利用性を最大化しつつ,定型的なプロセスは自動化することで,高速な仮説検証サイクルを回せられるということを目標としています.
これを冒頭で Researcher Experience の高いシステムと表現しました.
実験管理には OSS の MLOps ツールである MLflow と Hydra を利用しています.
以前『MLflowとHydraを利用した実験管理』という資料を作成したので,MLflow と Hydra の基本的な使い方についてはこちらも併せてご覧ください.
実験の実行方法
まず,以下のコマンドを実行することで実験が開始されます.
python src/federatedlearning/main.py
このときの実験の設定は,config ディレクトリ配下にある4つの YAML ファイルが参照され,その値が実験に使用されます.
config/default.yaml は親元の設定ファイルで,config/mlflow/default.yaml, config/train/default.yaml, config/federatedlearning/default.yaml を参照するように設定してあります.
defaults: - mlflow: default - train: default - federatedlearning: default
この親元の設定ファイルは基本的に変更する必要はなく,子である3つの設定ファイルを変更することで,コードを再利用しながら実験できます.
各設定ファイルの大まかな役割としては以下のとおりです.
config/mlflow/default.yaml: MLflow のexperiment_nameとrun_nameの設定config/train/default.yaml: クライアントが学習に利用するハイパーパラメータconfig/federatedlearning/default.yaml: 連合学習で使用するハイパーパラメータ
ArgumentParser を使用していないので,複雑な設定であってもスッキリした実行コマンドになります.
python src/federatedlearning/main.py
コマンドラインから設定を上書きした状態で実行することも可能で,以下のような書き方をすればその実験のときのみ規定値を上書きして実行できます.
なお,上書きした部分の設定は outputs/.hydra/overrides.yaml として記録されます.
python src/federatedlearning/main.py \
mlflow.run_name=exp001 \
federatedlearning.num_byzantines=0 federatedlearning.num_clients=10
また,Optuna によるブラックボックス最適化もできるようにしています.
オプション --multirun を付与して実行すると,設定された範囲の値の中で精度を最大化 / 最小化するパラメータの探索が行われます.
python src/federatedlearning/main.py \
--multirun 'federatedlearning.num_byzantines=range(8,13)'
Optuna の設定は,親元の設定ファイル config/default.yaml にある sweeper で設定されている値が参照されます.
sweeper: direction: minimize study_name: Byzantine-Resilient Federated Learning storage: null n_trials: 5 n_jobs: 1 sampler: seed: 42
direction が minimize であれば src/federatedlearning/main.py の main 関数を最小化,maximize であれば main 関数を最大化するように最適化されます.
実験が終わると,MLflow に記録された実験データを用いて可視化,検索,実験同士の比較ができるようになっています.
どのような設定でどのくらい精度が出たのかを実験管理できるのはかなり重宝します.
MLflow の WebUI を起動するコマンドは以下のとおりです.ポート 5000 番を使用します.
mlflow ui
ベースライン実験
FutabatedLearning は Communication-Efficient Learning of Deep Networks from Decentralized Data という論文のバニラ実装から派生させています.
つまり,基本的なアルゴリズムで紹介した FedAVG をベースラインとして実験が可能です.
ハイパーパラメータは可能な限り元の実装に近づけており,以下の設定で,CNN を使って IID に従う MNIST データセットを学習した結果は Accuracy 0.9703 でした.
# local batch size: B local_batch_size: 10 # learning rate lr: 0.01 # the number of local epochs: E local_epochs: 10 # type of optimizer optimizer: "sgd" # number of users: K num_clients: 100 # the fraction of clients: C frac: 0.1 # number of rounds of training rounds: 10

ビザンチン攻撃
連合学習が抱えるセキュリティの問題の1つである,ロバスト性保証の問題について,ビザンチン攻撃をやってみましょう.
ビザンチン攻撃の一種であるラベルフリップ攻撃 (Label-flip Attack) は極めてシンプルで,ミニバッチから取り出したラベルの情報 label を 9 - label と Index をずらします.
ラベルフリップ攻撃は,攻撃者がデータセットの中身を知らなくてもラベルの Index を操作するだけで攻撃ができるという攻撃者にとってのメリットがあります.
def labelflip_attack(label: torch.Tensor) -> torch.Tensor: """label-flipping failure Args: label (torch.Tensor): label tensor Returns: torch.Tensor: flipped label tensor """ return torch.Tensor(9 - label)
ベースライン実験に num_byzantines というパラメータを追加(規定値は0)し,全クライアントのうちの 60% がラベルフリップ攻撃をしてきたときの実験を行います.
# number of users: K num_clients: 100 # the fraction of clients: C frac: 0.1 # number of faulty workers num_byzantines: 60
ラウンドごとに選ばれるクライアントが変わるので同じ条件でも乱数によって結果が変わることが想定されますが,結果は Accuracy 0.0057 となりました.

ベースライン実験とこのラベルフリップ攻撃をした実験の比較を行ってみましょう.
MLflow は直感的な操作で可視化,検索,実験同士の比較ができるようになっています.



おわりに
本稿は,自作連合学習フレームワーク『FutabatedLearning』の紹介記事でした.
自作の実験環境によって自由な問題設定で実験を行うことができました.また,MLOps ツールを導入していることによって効率的な実験管理を実現しています.
今後は攻撃手法や防御(集約)手法の実装を増やして FutabatedLearning を拡張するとして,どうすれば Researcher Experience の高いシステムになるのだろうかと考えています.
はじめてのプレスリリース記事でした.
*1:Konečný, Jakub, et al. "Federated optimization: Distributed machine learning for on-device intelligence." arXiv preprint arXiv:1610.02527 (2016).
*2:Yang, Qiang, et al. "Federated machine learning: Concept and applications." ACM Transactions on Intelligent Systems and Technology (TIST) 10.2 (2019): 1-19.
*3:https://eur-lex.europa.eu/eli/reg/2016/679/oj
*4:https://www.ppc.go.jp/files/pdf/200612_houritsu.pdf
*5:McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial intelligence and statistics. PMLR, 2017.
*6:Krizhevsky, Alex, and Geoffrey Hinton. "Learning multiple layers of features from tiny images." (2009): 7.
*7:LeCun, Yann, et al. "Gradient-based learning applied to document recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324.
*8:Cohen, Gregory, et al. "EMNIST: Extending MNIST to handwritten letters." 2017 international joint conference on neural networks (IJCNN). IEEE, 2017.
*9:Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009.
*10:Lin, Tsung-Yi, et al. "Microsoft coco: Common objects in context." Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer International Publishing, 2014.
*11:https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
*12:Caldas, Sebastian, et al. "Leaf: A benchmark for federated settings." arXiv preprint arXiv:1812.01097 (2018).
*13:Fredrikson, Matt, Somesh Jha, and Thomas Ristenpart. "Model inversion attacks that exploit confidence information and basic countermeasures." Proceedings of the 22nd ACM SIGSAC conference on computer and communications security. 2015.
*14:Shokri, Reza, et al. "Membership inference attacks against machine learning models." 2017 IEEE symposium on security and privacy (SP). IEEE, 2017.
*15:Blanchard, Peva, et al. "Machine learning with adversaries: Byzantine tolerant gradient descent." Advances in neural information processing systems 30 (2017).