こんにちは、futabatoです。
y0d3nとl7elVliと『WAffle』というWAF(Web Application Firewall)を実装をしたので、成果物の開発記を書きました。
リポジトリはこちらになります。
WAffleのコンセプトとしては、正規表現によるパターンマッチングと機械学習で防御するWAFです。
denylistで定義済みのシグネチャを参照したパターンマッチングで弾けるものを弾いて、パターンマッチを抜けた通信に対して機械学習の推論処理を走らせるイメージです。

本稿では、WAffle開発記のうちの機械学習編を担当しています。
WAF/Vuln編はy0d3nが書いてくれています。シグネチャベースのWAFについてはそちらに詳しく書かれているので、合わせてご覧ください。
WAFに関して
WAFはFirewallやIDS/IPSが防ぐことのできないようなアプリケーション層レベルをはじめとした通信の可否を行います。 情報セキュリティには多層防御という考え方があるとおり、WAFはWebアプリケーションの実装面の根本的な対策になるわけではなく、攻撃による影響を低減する対策となります。
基本的にはホワイトリストやブラックリストといったシグネチャと呼ばれる通信パターンを事前に定義しておきます。ホワイトリスト方式は定義された通信のみが許可され、ブラックリスト方式では定義された通信のみ拒否される仕組みでWebアプリケーションを防御することになります。
しかし、状況に応じてパターンを定義したりシグネチャを更新したりする必要があり、WAFの導入にはコストがかかります。実際に、WAFの製品を見ていると導入コストで他社製品と差別化を図っている製品も見受けられます。
さらに、未知の悪意のある通信に対してはシグネチャベースの防御では対応することができないという課題があります。近年では機械学習的なアプロ―チで未知の通信に対しても遮断していく研究や製品が出てきています。
モデルの選定
WAFに機械学習を組み込むにあたって、まずは論文のサーベイを行いました。
いくつか見ていく中でWeb Application Firewall using Character-level Convolutional Neural Networkという良さそうな論文を見つけたので、詳しく読んでみることにしました。
良さそうと感じたのは、
We evaluated our system on HTTP DATASET CSIC 2010 dataset and achieved 98.8% of accuracy under 10-fold cross validation and the average processing time per request was 2.35ms.
とAbstractに記されているとおり、Accuracy 98.8と純粋な精度の高さから判断しました。
この論文に実装があれば再現実装をしてWAFに組み込んで終わりだったのですが、GitHubに実装が見つからなかったので自分の手で実装してみようと思いました。
実験条件などは可能な限りこの論文に近づけています。
モデルの概要
Web Application Firewall using Character-level Convolutional Neural NetworkはCharacter-level Convolutional Neural Networkという手法をベースにしています。
エンコードされたURLをInputとして、Outputは0に近いほど正常な通信、1に近いほど異常な通信となっている確率です。
WAFに組み込んだり評価したりする際には、出力された確率に対して0.5程度のしきい値を設けることで、正常か異常かを分類するようにしています。
Character-level Convolutional Neural Network
Character-level CNNの原著論文はこちらです。
文字レベルの畳み込みニューラルネットワークをテキスト分類に適用した論文となっています。
自然言語処理をDeep Learningで行う上でLSTMやRNNなどではおそらく文章の最小単位は基本的に単語とされていますが、Character-level CNNの最小単位は文字となっています。文字ベースで畳み込むことで単語に分ける必要もなく、日本語や文章でないURLなどにも応用することができます。
実装
コードはGitHubにて公開しています。
環境はGoogle Colaboratoryです。
フレームワーク選定
私のこれまでの経験としては、すでに完成している実装を自分の環境で再現をすることはありましたが、一から自分の手で実装をしたことはありませんでした。
実装を遂げるためには、詰まったときに人のコードを参照して理解ができることが重要だと考え、Kerasを選択しました。
GitHubでCharacter-level CNNの実装を検索した際に、Kerasのコードは何をしている処理なのか分かりやすく、なんとなく自分でも実装できそうと思えました。
PyTorchの方がKerasよりもパフォーマンス等の面で優れているところがあるでしょうが、とにかく自分でも実装できそうと思えたことを優先し、Kerasを選択することにしました。
勉強法としては、以下の記事を参考に、処理をイメージしながらとにかく写経することで肌感覚を掴みました。
実際にKerasの勉強に掛けた時間は1日、2日程度で非常に書きやすかったです。
Kerasのドキュメントもわかりやすく書かれているので、案外見様見真似で実装ができました。
Kerasのドキュメントだけを見ても実装ができるわけではありませんでした。
Character-level CNNを利用して分類タスクを解いている記事はいくつかあり、これらの記事は非常に参考になりました。
データセット
データセットは、HTTP DATASET CSIC 2010を利用しています。
このデータセットの選択した理由は、Web Application Firewall using Character-level Convolutional Neural Networkにて利用されていたデータセットだからです。
このデータセットは、スペインの電子商取引のWebアプリケーションのトラフィックをまとめたもので、35,000件以上の正常(Normal)な通信と25,000件以上の異常(Anomalous)な通信が含まれた60,000件以上のデータになっています。悪意のある通信の中には、XSS、SQLインジェクション、バッファオーバーフローを始めとするHTTP リクエストがあります。
もとのHTTP DATASET CSIC 2010データセットはそのままだとtext形式で少し扱いにくかったため、csv形式で公開されていないか探してみたところ、Kaggleにて公開されていたので、そちらを利用しました。
データセットの前処理
60,000件以上あるデータのうち、10%にあたる6,107件のデータをTestデータとして評価に用いています。機械学習の学習と検証のために全体の75%をTrainingデータ、15%をValidationデータとして使用しました。
HTTP DATASET CISC 2010 データセットは、異常か正常かのラベルやURL, Cookie, User-Agent, Pragmaなど、複数のカラムがありましたが、URLとラベルのみに限定してデータを利用しました。
URLデータの前処理
機械学習のネットワークに通す前にURLを特徴ベクトルに変換する前処理が発生します。
URLをすべて小文字に変換した後、URL Decode → Unicode Encodeをして、各URLデータの長さを1000に揃えるために後ろを0で埋めます。
最後にnumpyのarrayの型に変換することでInputデータを準備しました。
def load_data(urls, max_length=1000): urls = [s.lower() for s in urls] url_list = [] for url in urls: # url decode decoded_url = url_decode(url) # unicode encode encoded_url = [ord(x) for x in str(decoded_url).strip()] encoded_url = encoded_url[:max_length] url_len = len(encoded_url) if url_len < max_length: # zero padding encoded_url += ([0] * (max_length - url_len)) url_list.append((encoded_url)) # convert to numpy array url_list = np.array(url_list) return url_list
モデル作成
def create_model(input_max_size, embedding_size, kernel_sizes, dropout): # Input Layer # URLdecode -> Unicode encode -> numpy.darrayに変換されたURLをInputとして与える。 inputs = Input(shape=(input_max_size,), name='URL_input') # Embedding Layer x = Embedding(0xffff, embedding_size, name='Embedding')(inputs) x = Reshape((input_max_size, embedding_size), name='Reshape_into_128_legnth_vector')(x) # Convolution Layers convolution_output = [] for kernel_size in kernel_sizes: conv1 = Conv1D(64, kernel_size, activation='relu', padding='same', strides=1)(x) pool1 = MaxPool1D(pool_size=kernel_size, padding='same', strides=1)(conv1) conv2 = Conv1D(64, kernel_size, activation='relu', padding='same', strides=1)(pool1) pool2 = GlobalMaxPooling1D()(conv2) convolution_output.append(pool2) # concat output x = Concatenate(name='Concat_the_outputs')(convolution_output) # reshape into 256 length vector x = Reshape((256, ), name='Reshape_into_256_length_vector')(x) # Fully Connected Layers x = Dense(64, activation='relu', name='FullyConnectedLayer')(x) # Batch Normalization x = normalization.BatchNormalization()(x) # Dropout x = Dropout(dropout)(x) # Fully Connected Layers predictions = Dense(1, activation='sigmoid', name='Prediction')(x) model = Model(inputs=inputs, outputs=predictions, name='Character-level_CNN') return model
Character-level CNNの特徴としてはカーネルサイズの違う複数のカーネルでConvolutionして、それらをConcatenateするところにあります。 下の図を見ていただければ、そこは実現できているのかなと思います。
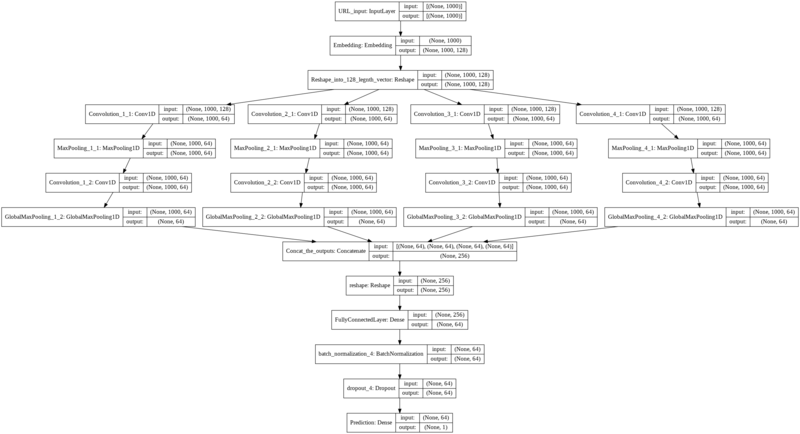
学習と検証
学習をさせてみると、おおよそうまくいってそうな雰囲気でした。
Validationデータの評価としては、Accuracy: 0.8606, Precision: 0.7691, Recall: 0.9476でした。

性能テスト
モデルの実装と同じように、性能テストを行ったコードはGitHubにて公開してあります。
環境はGoogle Colaboratoryです。
評価指標
話が前後しますが、評価指標にはAccuracy, Precision, Recall を使用しました。
ベースライン策定のためにいくつか論文をピックアップして調査を行いましたが、多くの場合使われていた評価指標はAccuracyでした。
PrecisionとRecallを評価指標にしている論文はあまり多くありませんでしたが、私が知りたかったために使用しました。
性能テスト
Kerasで実装をしたので、TestデータがあればKerasのメソッドを利用することですぐに精度が出せましたが、シグネチャベースのWAFを組み合わせることに工夫が必要でした。
モデルの評価をする分には、model.evaluate()を実行すればそれで十分ですが、WAffleの性能を評価したことにはなっていないので、少し頭を悩ませました。
解決策としては、Kerasのmodel.evaluate()は利用しませんでした。
PandasのDataFrameにURLとTargetに加え、パターンマッチ処理結果のy_match、モデルの推論結果のみのy_predの2つのカラムを作成しました。
y_predカラムは0.5のしきい値を適用することで、0, 1の分類しています。

y_matchとy_trueのOR演算をWAffleカラムとすることで、TargetとWAffleのカラムから混合行列を作成することができます。

この混合行列から、WAffleとしての性能を算出しました。

論文のAccuracy 98.8という結果には遠く及ばなかったものの、初めての論文実装でAccuracy: 86.4, Precision: 75.7, Recall: 99.3というまずまずな精度が出て安堵しています。

少しFalse Positiveが多いかなという感想は正直あります。
False PositiveとなったURLを見てみると重複しているURLがいくつかあったので、ブラックリスト方式のdenylistとは別に、ホワイトリスト方式のファイルを用意すればFalse Positiveを減らせて精度が向上するのではないかと思っています。
ただ、後出しでホワイトリストのファイルを作成するのは少しずるい気がしていて、ホワイトリストを作成しても一般的に使えるものにはならないので用意しませんでした。
WAFへの組み込み
WAffleのコンセプト通りパターンマッチングを行い、正規表現で引っかからなかった通信に対して推論処理を実行しています。
機械学習モデルをWAFに組み込むことはそこまで難しいことではありませんでした。
学習済みモデルをロードして、InputデータとなるURLに対して前処理を実行し、それ引数とするmodel.predict()を実行する関数を作成しています。
通信のログを残すために、WAffleを介した通信が何%異常だったのかを返り値としています。
def waf(url, path, body, cookie): if not signature(path, body, cookie): # パターンマッチングで引っかかった場合100%異常とする return 1 else: return prediction(url + path)
# 機械学習を使った推論処理 def prediction(url): # セッションのクリア(必要なのかは不明ではある) K.clear_session() model = load_model('../model/model.h5') model_input_url = preprocess(url) result = model.predict(model_input_url) return result[0][0]
waf関数の返り値はis_abnormalという変数に代入しています。
is_abnormalに0.5等のしきい値を設定することで通信を遮断するのか許可するのかという処理をしています。
パターンマッチングで弾くことのできた通信は100%異常な通信としてis_abnormalの値は1としています。
if is_abnormal >= 0.5: return render_template('waffle.html')
ログに関して
WAffleを介した通信は、すべてログを取っています。
内容はCSVファイルとして保存していて、Streamlitによって可視化することができます。
with open('../analysis/block.csv', 'a', newline='') as block_csv: block_writer = csv.writer(block_csv) block_writer.writerow([date_data, str(ip_data), path_data, body_data, cookie_data, is_abnormal])
取得すべきログは何か、どういう内容を可視化すべきかはWAFを利用する側の視点に立たないと考えづらいので、まだまだログの可視化については発展途上にあります。
おわりに
まともな成果物になるような開発はこのWAffleが初めてだったので、振り返りながらこの記事を書いてるときは少ししみじみとしました。
何かものをつくりたいなと思った時にy0d3nとl7elVliが話に乗っかってきてくれて、WAffleプロジェクトが始まりました。
プロジェクトのリーダー的なことをさせていただきましたが、はじめはチーム開発とは言えないようなぐちゃぐちゃ具合で非常に申し訳なかったですが、ひとまずの完成ができて本当に良かったなと思います。お二人には感謝です。
ものを作りながらセキュリティ関連を学べる教材として選択したWAFというテーマはとても良かったなと思います。
今後も手を動かしてものを作り続けていきたいと思います。
最後までご覧いただきありがとうございました。